# 概述
该文档用于介绍OpenNCC Software Development Kit (SDK) 并且包含了启动,运行及开发的所有必要信息。
# SDK结构
| 目录 | 内容 |
|---|---|
| ./Platform | 包含不同平台生成运行环境的脚本。 |
| ./SDK/docs | 包含SDK相关介绍和文档。 |
| ./SDK/Drivers | 包含不同平台所必须安装的驱动。 |
| ./SDK/Example | 包含SDK的相关例程。 |
| ./SDK/Source | 包含固件,模型及SDK库文件。 |
| ./SDK/Tools | 包含相关的模型转换及编译工具。 |
| ./Viewer | 包含已编译的Viewer及QT源码。 |
# 支持的产品及平台
SDK支持的产品如下:
OpenNCC DK
OpenNCC Lite
OpenNCC USB
SDK支持的平台如下:
Linux
Ubuntu 16.04, Ubuntu 18.04
Raspberry Pi(树莓派)
NVIDIA(英伟达)
Windows 10
SDK支持的语言如下:
- C/C++
- Python3.5、Python3.7
# SDK开发包目录结构
| 目录 | 内容概要 |
|---|---|
| Example/How_to/... /How_to_use_sdk | 示例程序,如何在项目中使用SDK库。 |
| Example/How_to/... /Capture_video | 示例程序,使用SDK库获取视频流。 |
| Example/How_to/... /Load_a_model | 示例程序,使用SDK库下载一个Blob格式的深度学习模型。 |
| Example/How_to/... /work_with_multiple_models | 示例程序,二级模型的应用。 |
| Example/How_to/... /python3 | Python的相关示例。 |
| Example/How_to/OpenNCC-EMMC | 包含eMMC版本的相关示例程序。 |
| Example/Linkage_demo /work with AlwaysAI /pedestrian_tracking_demo | 人脸模型,使用AlwaysAI解析结果显示,并统计通过识别区域的人数。 |
| Example/Linkage_demo /work_with_OpenVINO /human_pose_estimation_demo | 人体骨骼模型,使用OpenVINO解析结果显示。 |
| Example/Linkage_demo /work_with_OpenVINO /interactive_face_detection_demo | 人脸、年龄、性别、心情模型,使用OpenVINO解析结果显示。 |
| Example/Linkage_demo /work_with_PaddlePaddle | OCR文字识别示例程序,包含OpenNCC PaddlePaddle-OCR 仓库链接。 |
| Tools/myriad_compiler | IR文件转换成Blob文件工具 |
| Tools/deployment | 权限部署脚本 |
# 已集成的AI模型
| 模型类别 | 名称 | 简介 | 其他参考 |
|---|---|---|---|
| 物体分类 | classification-fp16 | ssd_mobilenet_v1_coco model can detect almost 90 objects | OpenVINO Doc Link (opens new window) |
| 人脸、人形检测 | face-detection-adas-0001-fp16 | Face detector for driver monitoring and similar scenarios. The network features a default MobileNet backbone that includes depth-wise convolutions to reduce the amount of computation for the 3x3 convolution block | OpenVINO Doc Link (opens new window) |
| face-detection-retail-0004-fp16 | Face detector based on SqueezeNet light (half-channels) as a backbone with a single SSD for indoor/outdoor scenes shot by a front-facing camera | OpenVINO Doc Link (opens new window) | |
| face-person-detection-retail-0002-fp16 | This is a pedestrian detector based on backbone with hyper-feature + R-FCN for the Retail scenario | OpenVINO Doc Link (opens new window) | |
| person-detection-retail-0013-fp16 | This is a pedestrian detector for the Retail scenario. It is based on MobileNetV2-like backbone that includes depth-wise convolutions to reduce the amount of computation for the 3x3 convolution block | OpenVINO Doc Link (opens new window) | |
| pedestrian-detection-adas-0002-fp16 | Pedestrian detection network based on SSD framework with tuned MobileNet v1 as a feature extractor. | OpenVINO Doc Link (opens new window) | |
| 人车、自行车 | person-vehicle-bike-detection-crossroad-0078-fp16 | Person/Vehicle/Bike detector is based on SSD detection architecture, RMNet backbone, and learnable image downscale block (like person-vehicle-bike-detection-crossroad-0066, but with extra pooling) | OpenVINO Doc Link (opens new window) |
| pedestrian-and-vehicle-detector-adas-0001-fp16 | Pedestrian and vehicle detection network based on MobileNet v1.0 + SSD. | OpenVINO Doc Link (opens new window) | |
| 车辆检测 | vehicle-detection-adas-0002-fp16 | This is a vehicle detection network based on an SSD framework with tuned MobileNet v1 as a feature extractor. | OpenVINO Doc Link (opens new window) |
| 口罩检测 | Mask-detect-fp16 | Mask detect | Under license |
| 车牌识别 | vehicle-license-plate-detection-barrier-0106-fp16 | This is a MobileNetV2 + SSD-based vehicle and (Chinese) license plate detector for the "Barrier" use case. | OpenVINO Doc Link (opens new window) |
| 人脸属性 | interactive_face_detection_demo | This demo executes four parallel infer requests for the Age/Gender Recognition, Head Pose Estimation, Emotions Recognition, and Facial Landmarks Detection networks that run simultaneously | OpenVINO Doc Link (opens new window) |
| 人体骨骼提取 | human-pose-estimation-0001-fp16 | A multi-person 2D pose estimation network (based on the OpenPose approach) with tuned MobileNet v1 as a feature extractor. | OpenVINO Doc Link (opens new window) |
# OpenVINO 安装和使用
在端侧部署一个深度学习模型,需要将一个训练完成的模型经过针对VPU特性的模型优化和转换,以达到较高的运行性能。OpenNCC兼容OpenVINO的工具集和模型格式,需要依赖Intel OpenVINO的模型优化器来完成模型优化和转换成Blob格式。使用OpenNCC SDK时需要安装OpenVINO的两种情况如下:
如果需要自行转换训练好的模型,那么需要安装OpenVINO,来运行模型优化器。
当OpenVINO运行在与OpenVINO推理引擎的混合模式时,也需要OpenVINO支持。
# 下载并安装OpenVINO
OpenNCC 目前支持OpenVINO版本:2020.3.194,OpenVINO安装教程
# Intel Free模型下载
OpenNCC支持OpenVINO下生产的模型,Intel有大量免费训练好的模型供学习参考和评测。当我们安装完成OpenVINO后,可以使用Intel下载工具下载模型集合。模型下载工具路径:openvino/deployment_tools/tools/model_downloader/downloader.py ,常用命令如下:
查看全部可下载的模型:./downloader.py --print
下载指定的模型:./downloader.py --name *
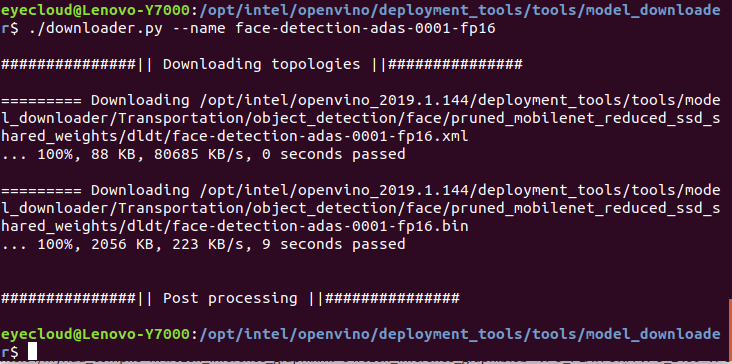
例如下载一个人脸检测模型 :./downloader.py --name face-detection-adas-0001-fp16
# 模型的优化和格式转换
当我们需要将一个训练好模型部署到OpenNCC时,需要对模型进行优化和转换。安装完成OpenVINO后,可通过模型优化工具 /opt/intel/openvino/deployment_tools/model_optimizer/mo.py 进行模型优化,具体文档见Intel官方文档: Model Optimizer Developer Guide (opens new window) 。
优化完成模型后,需要进行模型转换到Blob格式,才能在OpenNCC上进行部署。在OpenVINO安装目录 /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64下的myriad_compile工具,使用方法如下:
命令行终端下输入:/opt/intel/openvino_2020.3.194/deployment_tools/inference_engine/lib/intel64/myriad_compile -m input_xxx-fp16.xml -o output_xxx.blob -VPU_MYRIAD_PLATFORM VPU_MYRIAD_2480 -VPU_NUMBER_OF_SHAVES 6 -VPU_NUMBER_OF_CMX_SLICES 6 , 完成格式转换后,可在OpenNCC上部署模型,可参考:ncc_SDK/Samples/How_to/load a model,或者使用OpenView界面程序添加模型来部署测试。
# OpenNCC运行机制
从一个模型训练环境到嵌入式部署,是一个非常重要的工作,需要对深度学习的框架掌握,如常用的:Caffe*, TensorFlow*, MXNet*, Kaldi* 等。此外掌握部署的嵌入式平台非常重要,需要了解平台性能,系统架构特点,结合平台特点需要对训练的模型框架进行优化,并最后调优移植部署到嵌入式平台。OpenNCC专注于深度学习模型的快速部署,兼容Intel OpenVINO,并针对嵌入式图形图像应用场景,在端侧完成了从2MP到20MP不同分辨率传感器集成,端侧实现了可部署专业级别的ISP,可将OpenVINO优化转换后的模型文件动态下载到端侧OpenNCC相机,实现深度学习模型的快速部署。同时OpenNCC设计了独立工作模式、混合开发模式和协处理计算棒模式来适配不同的工作应用场景。
# OpenNCC独立模式
独立模式下,OpenNCC独立运行一个深度学习模型,并将推理结果通过OpenNCC SDK API反馈给用户。
应用程序部署流程如下图:
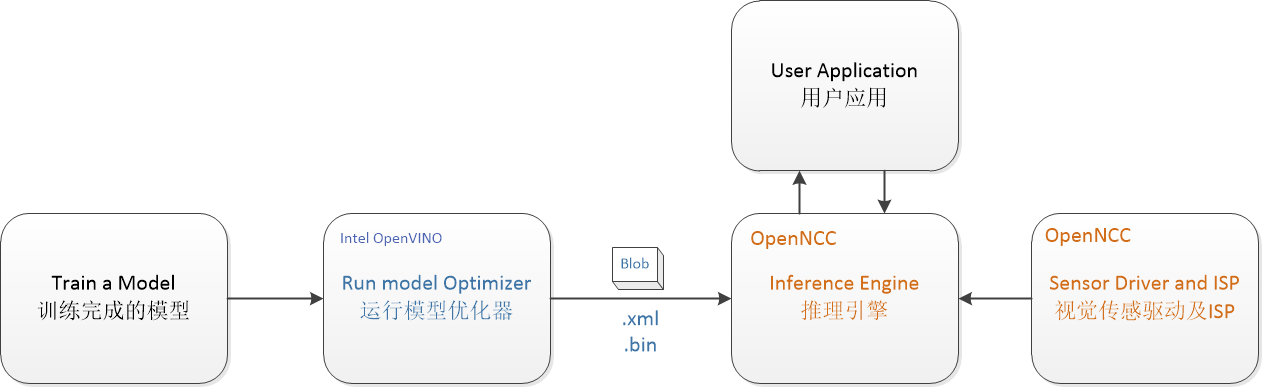 按照OpenVINO文档,为特定的训练框架配置模型优化器(Configure Model Optimizer) (opens new window)
按照OpenVINO文档,为特定的训练框架配置模型优化器(Configure Model Optimizer) (opens new window)
运行模型优化器(Model Optimizer) (opens new window),基于训练好的网络拓扑、权值和偏差值等可选参数产生一个优化后的IR文件,IR是一对描述整个模型的文件,包括.xml文件--拓扑文件-描述网络拓扑的XML文件,以及.bin文件--训练后的数据文件-一个包含权重并偏置二进制数据的.bin文件,然后再运行myriad_compile将IR文件生成BLOB文件。
在应用程序上,集成使用OpenNCC SDK下载优化完成后的BLOB模型文件,见SDK下Example/How_to/Load_a_model的演示程序。
OpenNCC View是集成了OpenNCC SDK的带操作界面的应用演示程序,也可以使用OpenView来部署模型,获取测试结果。OpenNCC View 使用文档。由于不同的深度模型有差异化的推理输出结果,OpenNCC SDK对不同格式结果支持在不断增加中,如果用户无法在SDK下找到合适的后处理解析模型,需要自己参考Example/How_to/Load_a_model并结合自己应用场景来编写后处理代码。
# 二级模型运行支持
考虑到端侧算力,目前SDK多级模型支持到两级模型级联,如图:
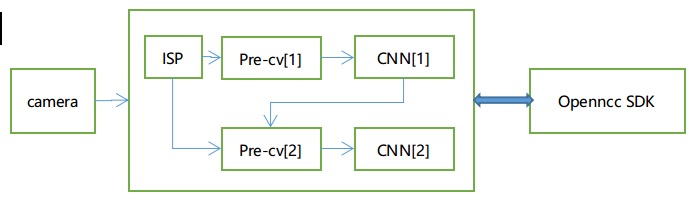
第一级模型必须为目标检测或者分类模型,且输出定义如下:

推理流程:
1)图像先经过Pre-cv[1] ,把原图scale到一级模型输入大小,并做相应的格式转换,然后做一级模型推理计算,并且把一级推理结果输出到Pre-cv[2]. 2) Pre-cv[2] 模块解析第一级模型的推理结果,把符合条件的label和conf的检测目标,根据坐标起点(x_min, y_min), 终点(x_max,y_max)从 原图crop和scale到二级模型输入大小,并做相应的格式转换,进入第二级模型推理。
3)最后把一级模型和全部的二级模型推理结果打包在一起输出。
模型输出解析(图示参数配置为,有效label:2,3,conf=0.8):
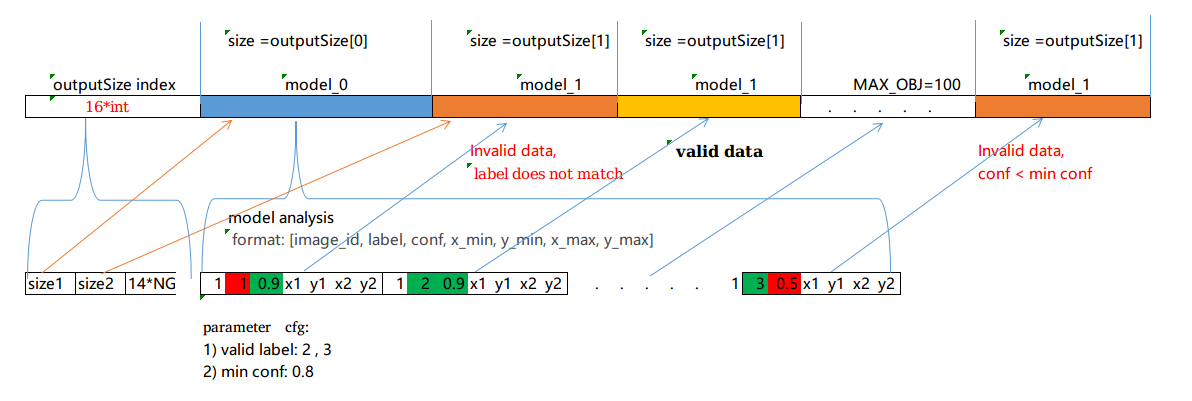
示例程序:Example/How_to/... /work_with_multiple_models,第一级模型为车辆和车牌检测,第二级模型是车牌检测,设置有效的label为2。
基于第一级的检测结果,适当微调第一级的检测坐标,有利于识别:
*起点向左上方微调(startXAdj,startYAdj )
*底点向右下方微调(endXAdj,endYAdj)
cnn2PrmSet.startXAdj = -5;
cnn2PrmSet.startYAdj = -5;
cnn2PrmSet.endXAdj = 5;
cnn2PrmSet.endYAdj = 5;
# OpenNCC 混合模式
当需要解决一些复杂应用场景,需要多个网络模型组合处理、OpenNCC端侧计算性能无法满足、或者端侧处理完成后需要到边缘侧集中后处理时,往往需要进行系统扩增。将实时性诉求高的模型运行在OpenNCC端侧,其他模型运行在后处理边缘机或云端。
如图,Model-1运行在OpenNCC端侧,完成对视频流的前处理。OpenNCC将一级处理模型结果返回用户应用程序,Model-1和Model-2完全运行于OpenVINO推理引擎下,实现后续处理。
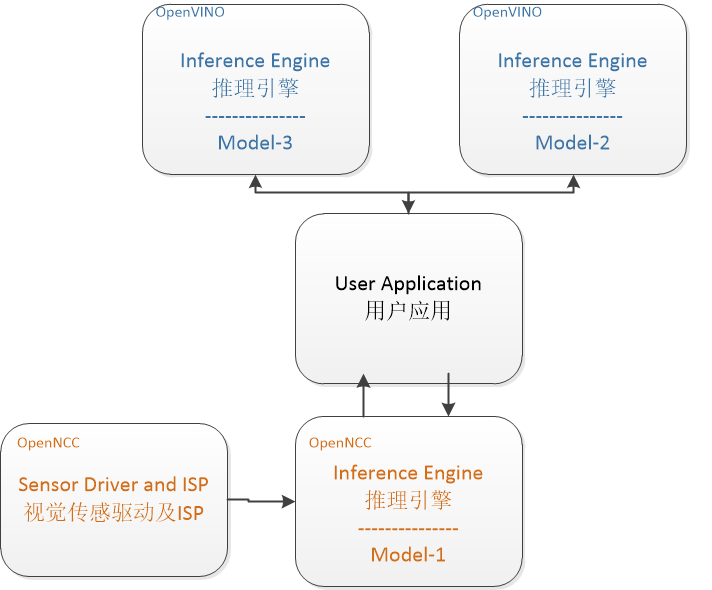
Examples/Linkage_demo/work_with_OpenVINO 演示了如何让OpenNCC和Host PC上OpenVINO组合实现一个分布式AI系统。
# 协处理计算棒模式
OpenNCC的协处理模式,类似与Intel NCS2计算棒。这种工作模式下,OpenNCC的视觉传感器不工作,用户可以单独使用OpenNCC 来实现完全兼容OpenVINO环境。OpenVINO典型的深度学习模型部署流程如下:
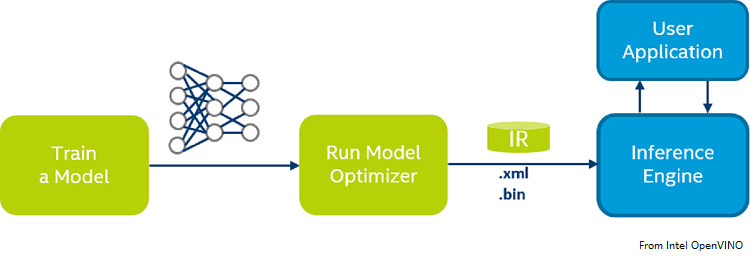
按照OpenVINO文档,为特定的训练框架配置模型优化器(Configure Model Optimizer) (opens new window)产生一个优化后的IR文件,基于训练好的网络拓扑、权值和偏差值等可选参数。
将优化生成的IR文件下载到OpenNCC上运行推理引擎(Inference Engine) (opens new window),具体参考OpenVINO文档:Inference Engine validation application (opens new window) 和 sample applications (opens new window) 。
将Source/Firmware/fw /usb-ma2x8x.mvcmd复制并且替换openvino安装目录下的openvino/inference_engine/lib/intel64/usb-ma2x8x.mvcmd.(备注:替换前必须备份usb-ma2x8x.mvcmd,使用NCS2推理时需要恢复该文件)
# 独立模式和协处理模式区别
如下图右侧是OpenNCC的独立模式,左侧是OpenNCC的协处理模式(类同Intel NCS2)。
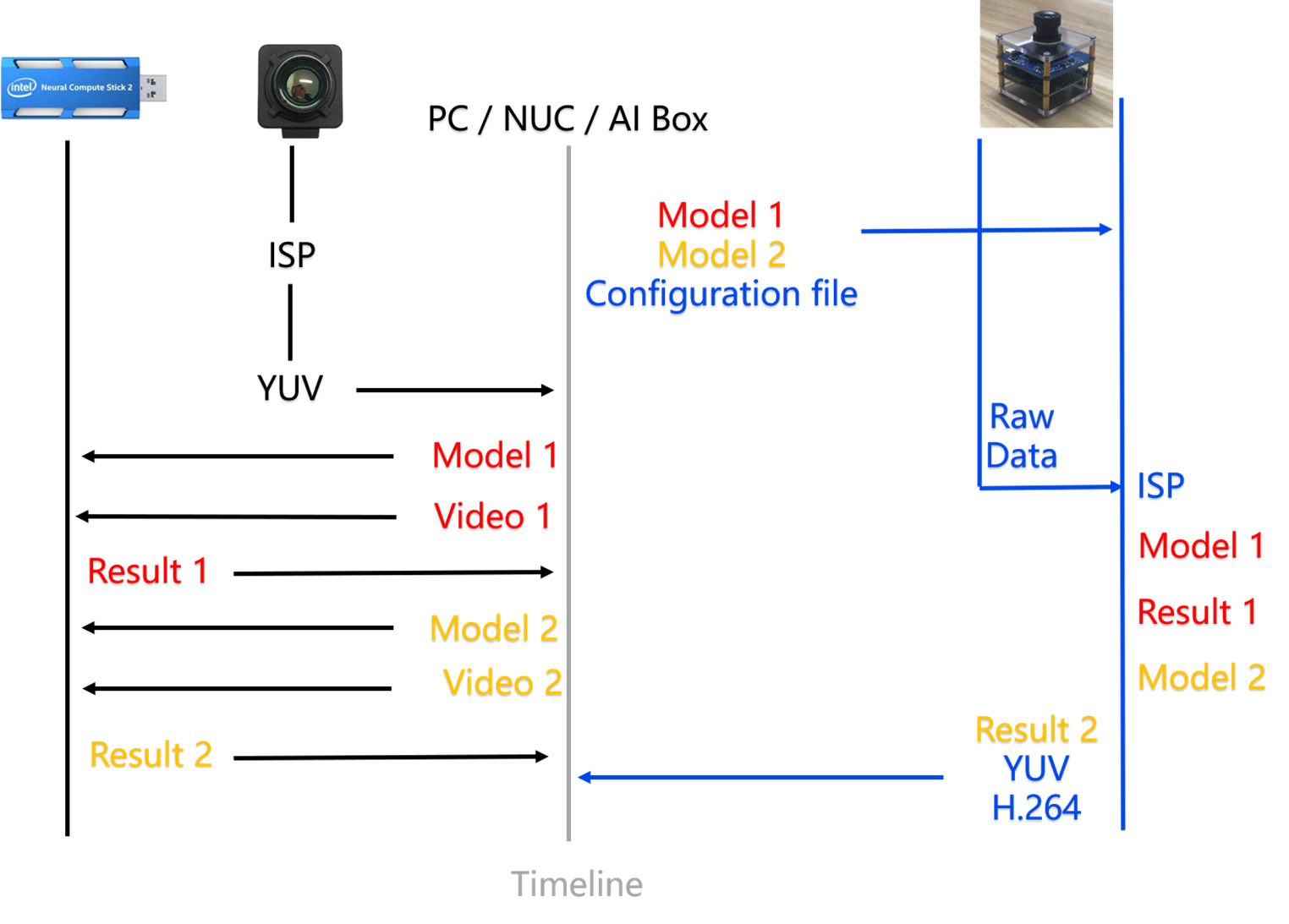 当我们需要部署一个基于视觉的深度学习模型时,首先我们需要获取一个高质量的视频流,然后运行推理引擎来把输入的图像数据进行计算,最后输出结果。左侧的协处理模式,我们需要一个OpenNCC 或者Intel NCS2实现端侧推理,同时我们需要从一个摄像机获取视频流,并将视频帧通过USB发送给OpenNCC。而右侧的独立模式,不需要额外的摄像机来获取视频流,我们只需要将模型下载到OpenNCC后,就可以获取到推演结果。
当我们需要部署一个基于视觉的深度学习模型时,首先我们需要获取一个高质量的视频流,然后运行推理引擎来把输入的图像数据进行计算,最后输出结果。左侧的协处理模式,我们需要一个OpenNCC 或者Intel NCS2实现端侧推理,同时我们需要从一个摄像机获取视频流,并将视频帧通过USB发送给OpenNCC。而右侧的独立模式,不需要额外的摄像机来获取视频流,我们只需要将模型下载到OpenNCC后,就可以获取到推演结果。
参考OpenVINO官网:https://docs.openvinotoolkit.org/