# 准备工作
# 下载Software Development Kit(SDK)
- 进入官网 (opens new window)
- 点击→访问SDK仓库
- 下载压缩包或复制地址使用Git克隆即可。
下载完成后进入openncc/Platform,目录如下图:
└─ Platform
├─ Linux
| └─ NVIDIA
| └─ RaspberryPi
| └─ Ubuntu
├─ Windows
├─ Custom
├─ README.md
选择需求的文件目录进入,对应文件夹内包含环境搭建的脚本。
警告:环境搭建脚本会自动生成和覆盖相关文件,运行前请确认是首次运行或已经完成备份。
# 快速入门之linux
# 环境搭建
- 进入目录
opennccc/Platform/Linux/Ubuntu。 - 右键打开终端。
- 输入命令
./build_ubuntu.sh。
生成目录如下:
└─ Ubuntu
├─ Example
├─ Source
├─ Viewer
├─ build_Ubuntu.sh
├─ README.md
# OpenNCC_Linux操作演示
进入openncc/Platform/Linux/Ubuntu/Viewer/OpenNcc_Linux 目录。
右键打开终端,执行
sudo ./AppRun,启动软件。连接OpenNCC相机到电脑USB 3.0接口,点击
Get device info按钮获取设备信息,此时log区域会有两种提示:- USB3.0:USB interface is 3.0, yuv outflow is currently available。
- USB2.0:USB interface is not 3.0, yuv outflow will be disabled。
提示:OpenNCC TYPE-C接口有正反接入两种模式,分别对应USB3.0 和 USB2.0。受传输速率影响,USB2.0模式下会暂时禁用YUV420P格式的视频流输出 。
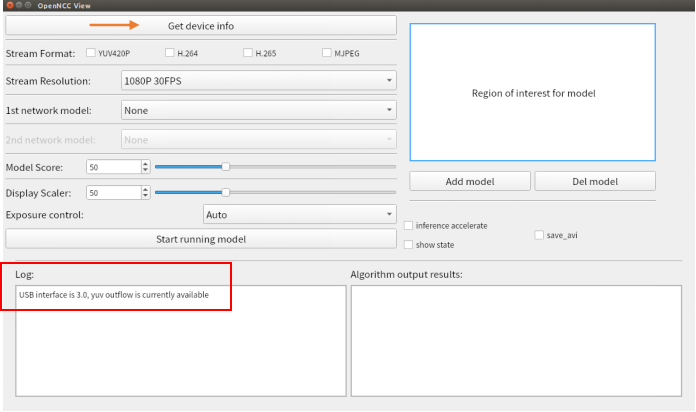

如果需要切换USB模式,旋转TPYE-C接口再次接入,重新点击Get device info按钮即可。如果仍然没有改变,请检查电脑USB接口类型或联系我们 (opens new window)。
任意选择一种视频流格式 yuv420p/H.264/H.265/mjpeg。
Stream Resolution:两种分辨率可供选择,1080p和4K。(具体由OpenNCC产品类型决定)
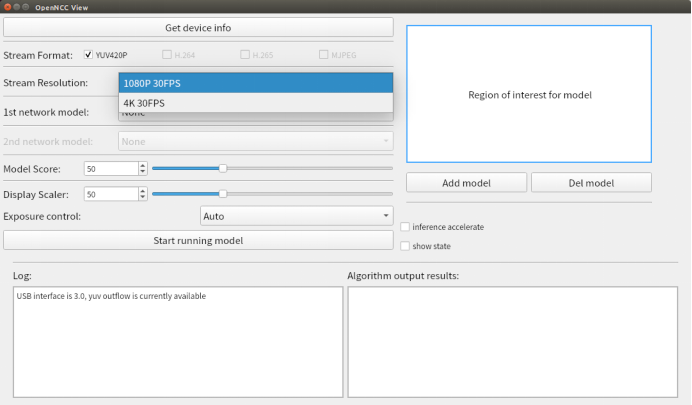
1st network model:选择算法模型。
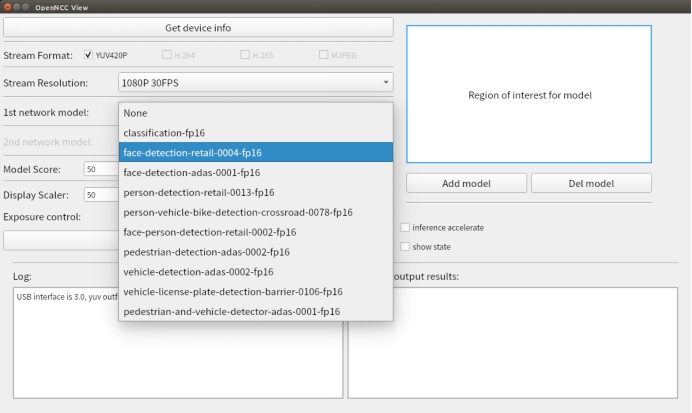
目前支持10多种模型可选,选择None即不加载模型,仅显示原始视频流。
- 可以通过框选ROI区域限制算法区域,算法只对区域内的场景进行识别。
(具体见运行结果展示)
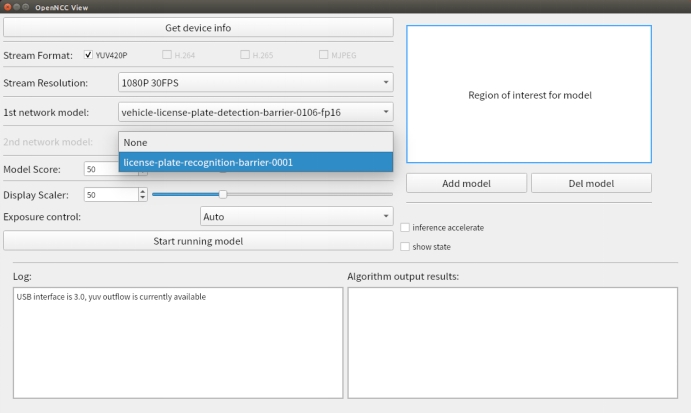
2nd network model:选择二级算法模型。
示例模型:vehicle-license-plate-detection-barrier-0106-fp16
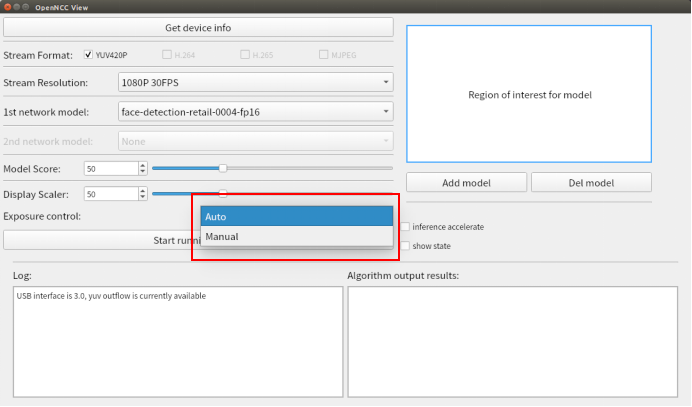
Model Score:设置算法识别的最低分数,达到阈值后才会在画面中框选出识别结果。Display Scaler:设置视频显示窗体大小,可以调节显示窗口分辨率。Exposure control:设置曝光,可以选择Auto和Manual,当选择Manual时,可以自己设置Exposure times和iso。
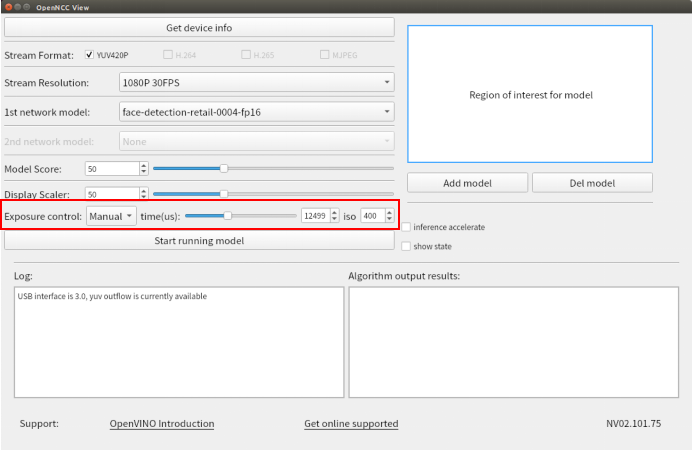
- 勾选
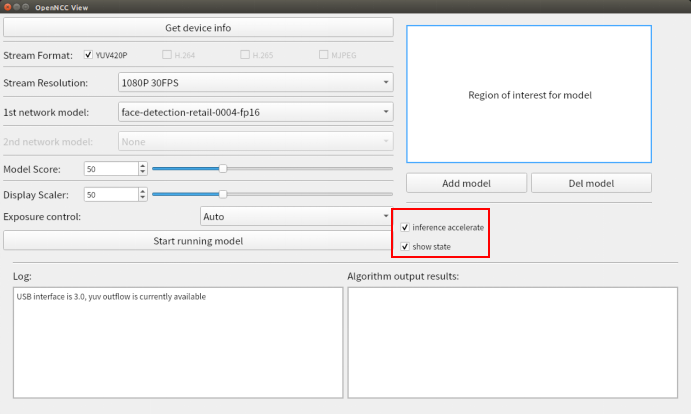
show state,选择是否在画面上显示当前状态信息,包括视频流帧率、算法帧率、分辨率、设备id。 - 勾选
inference accelerate,选择是否启用算法加速.(必须在加载算法模型前选择)。
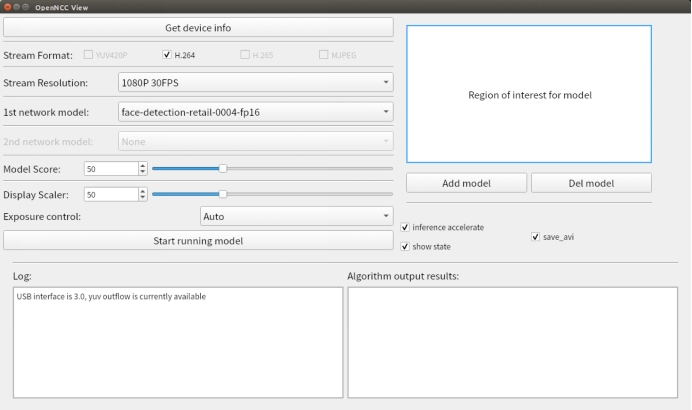
- 勾选
save_avi,视频将在打开视频流后,以时间命名的avi文件保存到目录openncc/Platform/Linux/Viewer/OpenNcc_Linux /avi文件夹下。当关闭视频流后,视频会停止保存。(yuv420p没有此项)
# 快速入门之Windows
# 环境搭建
进入openncc/Platform/Windows
双击运行
build_windows.bat。结果如下:
└─ Windows
├─ Source
├─ Viewer
├─ build_windows.sh
├─ README.md
- 脚本运行成功后,进入openncc/Platform/Windows/Drivers目录, 安装Windows USB驱动。详细安装步骤见 OpenNCC_USB_Driver_install_guide_win.pdf。
# OpenNCC_Windows操作演示
- 进入openncc/Platform/Windows/Viewer/OpenNcc_Windows 目录。
- 双击运行
OpenNCC.exe。 - 后续操作同OpenNCC_Linux
# 快速入门之Raspberry Pi
# 环境搭建
打开终端
进入openncc/Platform/Linux/RaspberryPi
输入命令
./build_raspberryp.sh。
运行成功后,会生成目录如下:
└── Raspberry
├── Example
├── Source
├── Viewer
├── build_raspberrypi.sh
├── README.md
# OpenNCC_Raspberry 操作演示
提示:运行OpenNCC_Raspberry之前,请先查看设备号并联系我们 (opens new window)获取密钥,设备号获取方法详见 openncc/Platform/Raspberry/ReadMe.md
- 将密钥文件(eyecloud.key)复制到目录openncc/Platform/Linux/RaspberryPi/Viewer/OpenNcc_Raspberry/Configuration/fw
- 回到目录l openncc/Platform/Linux/RaspberryPi/Viewer/OpenNcc_Raspberry
- 打开终端,执行
sudo ./AppRun,启动软件。 - 后续操作同OpenNCC_Linux。
# 快速入门之NVIDIA
# 环境搭建
- 进入目录
opennccc/Platform/Linux/NVIDIA。 - 右键打开终端。
- 输入命令
./build_nvidia.sh。
运行成功后,会生成目录如下:
└─ NVIDIA
├─ Example
├─ Source
├─ build_nvidia.sh
├─ README.md
# 快速入门之YOLO数据的云端推送
# 环境搭建
提示:本操作基于上述几个平台的opencv,libusb等基础环境已经搭建完毕。
- 在此基础上,针对ubuntu和Raspberry
install curl:
$ cd ~
$ wget http://curl.haxx.se/download/curl-7.57.0.tar.gz
$ tar -xzvf curl-7.57.0.tar.gz
$ cd curl-7.57.0/
$ ./configure
$ make
$ sudo make install
树莓派环境下make时可能出现报错,如果有,请执行如下操作
$ cd curl-7.57.0/lib
打开content_encoding.c 文件
将第549行删除
- 针对NVIDIA
1.install zlib:
$ down from http://zlib.net/zlib-1.2.5.tar.gz
$ tar zxf zlib-1.2.5
$ cd zlib-1.2.5
$ mkdir zlib_install
$ export CC=gcc
$ ./configure --prefix=/home/zlib-1.2.5/zlib_install
$ make -j8
$ make install
2.install openssl:
$ down from https://www.openssl.org/source/openssl-3.0.1.tar.gz
$ tar zxf openssl-3.0.1.tar.gz
$ cd openssl-3.0.1
$ mkdir openssl_install
$ ./config no-asm shared --prefix=/home/openssl-3.0.1/openssl_install
$ make -j8
$ make install
3.install curl:
$ wget http://curl.haxx.se/download/curl-7.57.0.tar.gz
$ tar -xzvf curl-7.57.0.tar.gz
$ cd curl-7.57.0/
$ ./configure --with-openssl=/home/openssl/openssl_install
$ make
$ make install
# 简介
该程序旨在帮助用户方便地在OpenNCC上使用YOLO模型,包括YOLO的训练和转化,模型在OpenNCC设备上的部署,识别结果的打包并上传云端。
提示:本演示已带默认生成的yolo模型数据。
# 操作演示
打开终端
针对不同平台进入openncc_cdk/Platform/Linux/NVIDIA
或者 openncc_cdk/Platform/Linux/Raspberry
或者 openncc_cdk/Platform/Linux/Ubuntu
相对应输入命令
./build_nvidia.sh或者build_raspberrypi.sh或者./build_ubuntu.sh。运行成功后,会相应生成目录
进入
Example/How_to/OpenNCC/C&C++/How_to_use_sdk目录输入命令
make all编译成功后进入bin目录
cd ./bin输入命令
sudo ldconfig输入命令
sudo ./OpenNCC 5执行程序
提示:程序首次运行请查看终端打印获取该设备的设备号,请联系我们 (opens new window)为该设备开通云端权限。
- 程序设定是每10秒检测到任意模型即上传一张图片至云端
- 云端网址:
https://ircam.eyecloudtech.com/#/device
# 关于YOLO模型训练
介绍如何进行模型训练,训练获得的数据提供给OpenNCC_YOLO使用。
# 安装环境依赖
CMake >= 3.18*
https://cmake.org/download/Powershell* (already installed on windows)
https://docs.microsoft.com/en-us/powershell/scripting/install/installing-powershellCUDA >= 10.2*(可选)
https://developer.nvidia.com/cuda-toolkit-archivecuDNN >= 8.0.2*(可选)
https://developer.nvidia.com/rdp/cudnn-archive- (on Linux follow steps described here)
https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installlinux-tar
- (on Linux follow steps described here)
- (onWindows follow steps described here)
https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installwindows)
- (onWindows follow steps described here)
GPU with CC >= 3.0*(可选)
https://en.wikipedia.org/wiki/CUDA#GPUs_supported
# 训练工具编译
git clone https://github.com/AlexeyAB/darknetcd darknet
mkdir build_releasecd build_release
cmake ..
cmake --build . --target install --parallel 8
# 准备数据集
- 训练集图片放在train文件夹内,验证集放在val文件夹内
# 数据标注
git clone https://hub.fastgit.org/AlexeyAB/Yolo_mark.git
cmake .
make
./linux_mark.sh
- 关于标注的使用方法可查看Yolo_mark目录内的readme.md
# 参数配置
- 除两个数据集外,启动训练还需要配置几个参数文件,包括obj.data,obj.name,train.txt。
以上三个文件,会在数据标注时自动生成在Yolo_mark/x64/Release/data目录下:
obj.name文件包含所有目标的类别名,train.txt包含所有训练图片路径,val.txt非必须,可以手动从train文件中分割出30%的图片用于验证。而obj.data文件申明了上述所有文件的路径和类别总数,如果使用自己的数据集,对应参数修改请在标注前完成修改。
- yolo.cfg(拓扑)
Yolo.conv(预训练权重) cfg和conv存在一定对应关系,考虑此处训练的模型最终需部署在openncc上,推荐使用(yolov4-tiny.cfg+yolov4-tiny.conv.29)或(yolov3-tiny.cfg+yolov3-tiny.conv.11)的搭配,cfg文件可以直接在darknet/cfg目录下找到。 Cfg文件修改!! 如果目标类别数量不等于80,则必须修改cfg文件。 搜索cfg文件中所有yolo层的位置,若总共有3 类目标,则将[yolo]层classes参数定义为3,再将[yolo]上一层[convolutional]层的filters定义为24.计算方式为filters=(classes+5)*3。 对yolov4-tiny.cfg来说有两个yolo层,所以一共需要修改4个参数。
# 启动训练
第二步编译成功后,会在darknet目录下生成./darknet工具。
输入命令:
./darknet detector train ./obj.data ./yolov4-tiny.cfg ./yolov4-tiny.conv.2
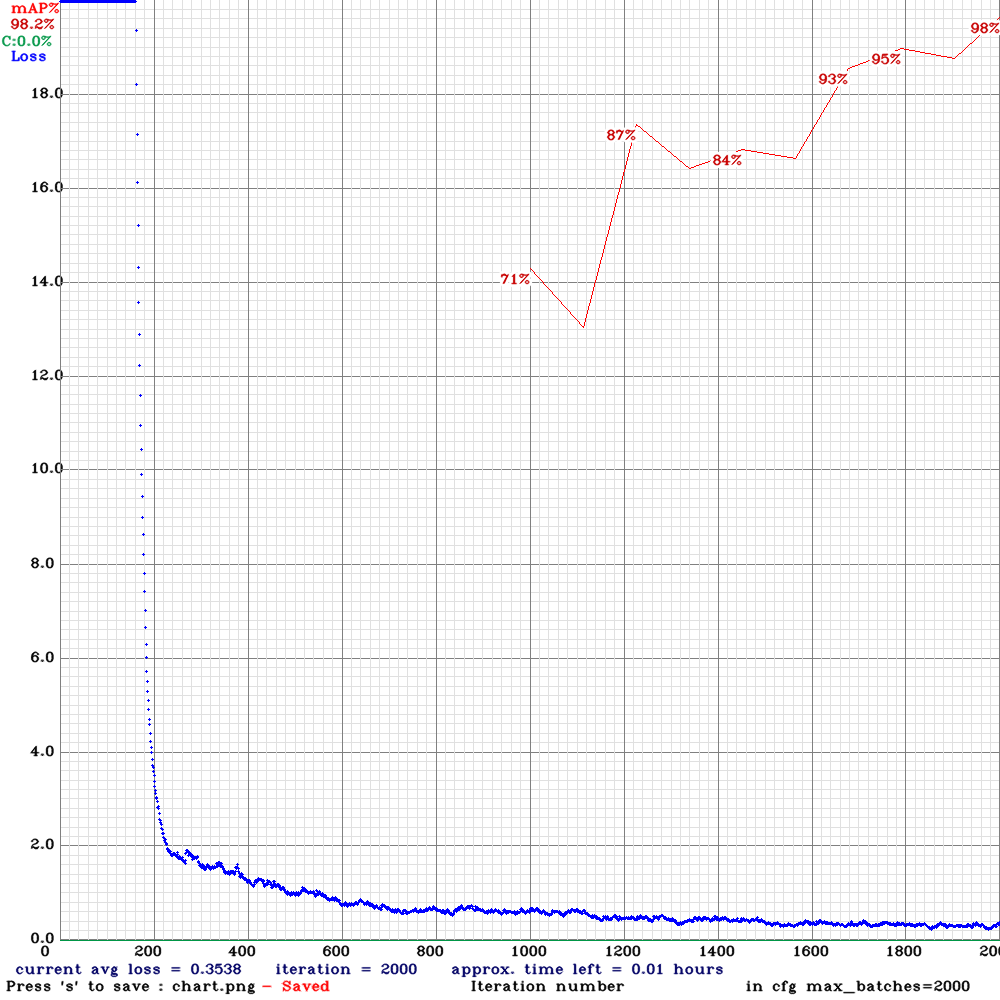
如果你使用显卡训练,显存小于8G的显卡,需要在cfg的第一层[net]中将batch参数改到8以下(8,4,2,1)。 若训练进行顺利,可看到如下图的训练日志图表。 训练结束后,可看到一系列.weights文件。这里还是建议制作数据集时设置一个验证集,这样可以直接锁定验证集中map最高的权重yolov4-tiny_best.weights作为后续使用。
- Darknet to tensorflow
git clone https://github.com/RenLuXi/tensorflow-yolov4-tiny.git
cd tensorflow-yolov4-tiny
python convert_weights_pb.py --class_names obj.names --weights_file yolov4-tiny_best.weights --tiny
这里需要用到第五步中obj.names和yolov4-tiny_best.weights.
- Tensorflow to IR(openvino推理格式)
修改json配置文件 打开tensorflow-yolov4-tiny目录下的yolo_v4_tiny.json,将其中的classes值修改为你自己的类别数,openvino进行tensorflow转换需要用到这个文件。 然后替换json配置文件
$ cp ./yolo_v4_tiny.json /opt/intel/openvino/deployment_tools/model_optimizer/extensions/front/tf
进入openvino模型转换工具目录
$ cd /opt/intel/openvino/deployment_tools/model_optimizer
转换命令
$ python mo.py --input_model yolov4-tiny.pb --transformations_config ./extensions/front/tf/yolo_v4_tiny.json --batch 1 --data_type FP32 --reverse_input_channels
- IR to blob 老办法,先初始化openvino环境,然后把上一步生成的xml和bin文件丢过去转换
source /opt/intel/openvino_2020.3.194/bin/setupvars.sh
cd /opt/intel/openvino_2020.3.194/deployment_tools/inference_engine/lib/intel64
cp /opt/intel/openvino/deployment_tools/model_optimizer/yolov4-tiny.xml ./
cp /opt/intel/openvino/deployment_tools/model_optimizer/yolov4-tiny.bin ./
/opt/intel/openvino_2020.3.194/deployment_tools/inference_engine/lib/intel64/myriad_compile -m yolov4-tiny.xml -o yolov4-tiny.blob -VPU_MYRIAD_PLATFORM VPU_MYRIAD_2480 -VPU_NUMBER_OF_SHAVES 6 -VPU_NUMBER_OF_CMX_SLICES 6
# 使用模型
- 转化完成后,至此,已经获得了在OpenNCC上部署所需的全部模型文件,xml,bin和blob。
# Custom(自定义)
# 环境搭建
进入openncc/Platform/Custom。
右键打开终端。
输入命令
./custom.sh
提示:如需在自定义平台运行,请联系我们 (opens new window)获取定制化服务。
# 运行结果演示
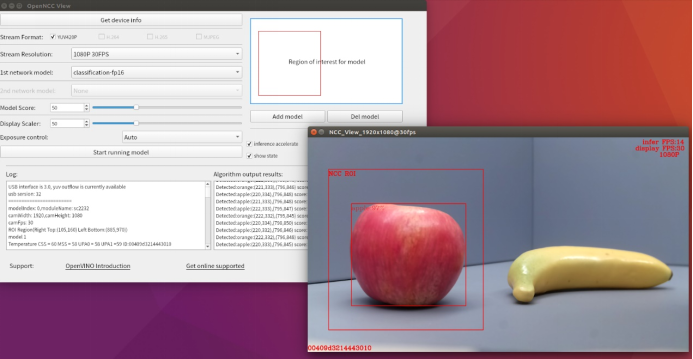
以物体分类算法模型为例:
香蕉在算法区域内结果:
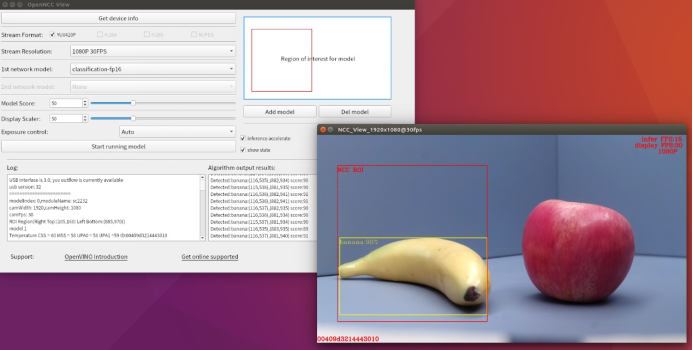
苹果在算法区域内结果: